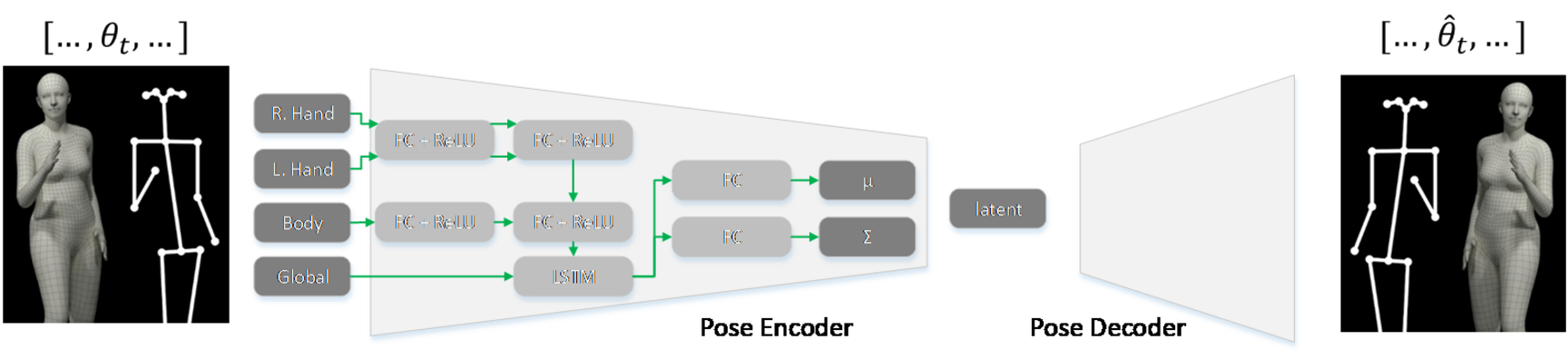
Doing gestures while speaking is an important aspect in virtual agents, as it adds to the credibility of a character. However, generating body motion from a speech input is a difficult task. For instance, mapping from speech to gestures has a non-deterministic nature. Our current work consists of using deep neural networks to learn gesticulation skills from human demonstrations. More specifically, we train a variational auto-encoder on human pose sequences to learn a latent space of human gestures. We later train an additional network to learn a mapping from speech features to the latent representation of gestures.
More information will follow.