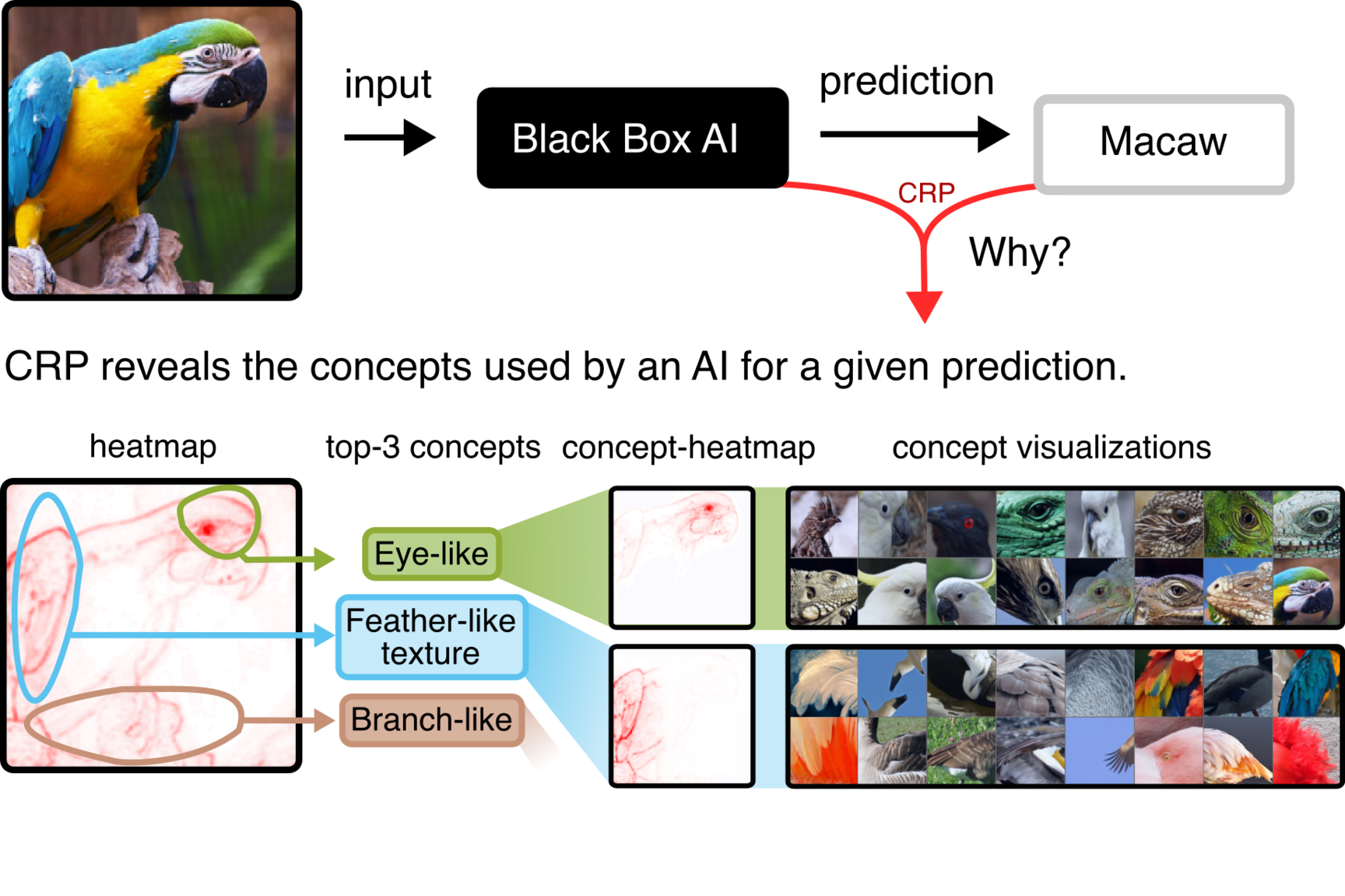
CRP is a cutting-edge explainability method for deep neural networks that allows for the understanding of AI predictions on the concept level. As an advancement of LRP, CRP indicates not only which input features are relevant, but also communicates which concepts are used, where they are located in the input and which parts of the neural network are responsible. Thus, CRP sets new standards in AI validation and interaction with a high level of human-understandability.
The research of the eXplainable AI group fundamentally focuses on the algorithmic development of methods to understand and visualize the predictions of state-of-the-art AI models.
In 2022, our group introduced Concept Relevance Propagation (CRP) [1] to explain the predictions of deep neural networks (DNNs) on the concept level in a human understandable way. As an extension of our Layer-wise Relevance Propagation (LRP) [2] method, CRP allows a deeper model understanding compared to traditional heatmap-based approaches. Whereas traditional heatmaps show the overall relevant input features for a prediction outcome, CRP disentangles the explanation into the contributions of individual concepts (learned by the AI) during individual predictions.
Concretely, CRP communicates which hidden concepts a model has learned, to which degree each concept contributes to a prediction, and precisely locates the concepts in the input data.
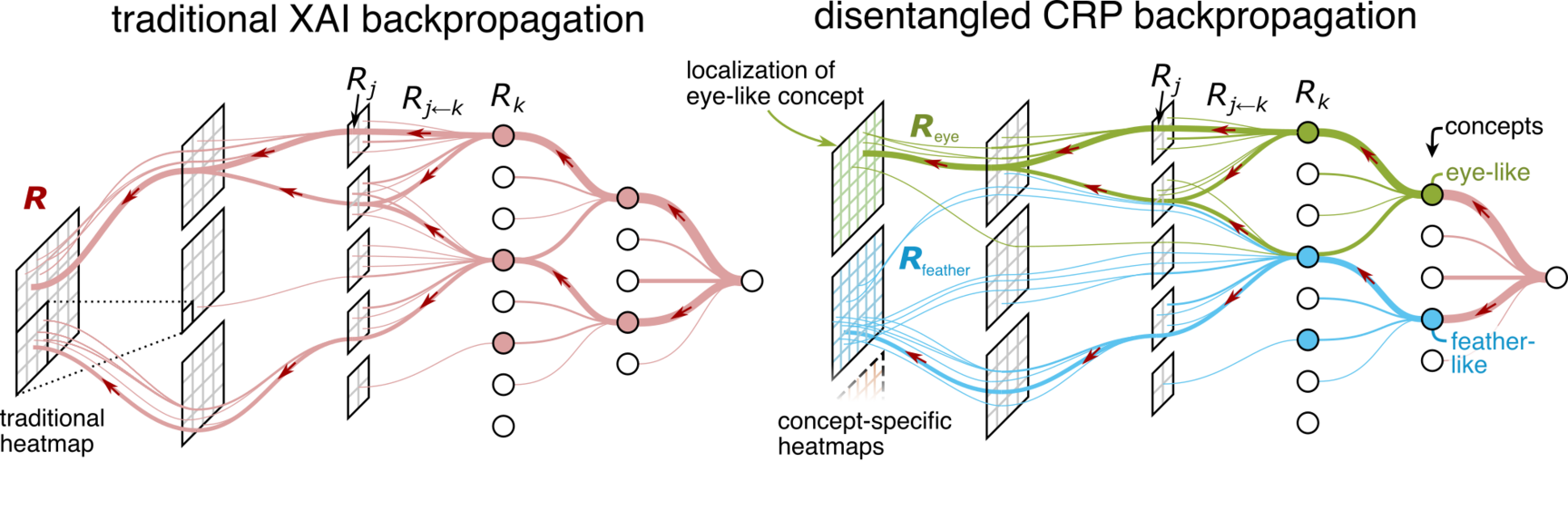
The application of CRP consists of a pre-processing step (that is performed once) and an ad-hoc step specific to the model prediction of choice.
In the pre-processing step, the example visualizations for concepts in the model's hidden space are collected from arbitrary data sources. Besides finding visualizations leading to strong stimuli (as is the common approach in the literature), we propose Relevance Maximization, which refines the visualizations showing more precisely how the model uses a concept.
In the ad-hoc step, firstly, a traditional XAI explanation is computed for a model prediction of choice by propagating relevance scores from the output to the input, layer by layer. During this backward pass, the relevances of latent concepts are determined.
To also precisely localize concepts in the input data, CRP introduces the idea of conditional relevance computation. Specifically, for a concept of interest, the backward pass is restricted to the concept's relevant paths, resulting in a concept-specific heatmap.
Together, CRP visualizes concepts and communicates for a prediction outcome of choice, which hidden concepts are relevant and precisely localizes the concepts in the input, rendering complex AI prediction processes readily interpretable to non-experts/AI users.
The concept-based explanations of CRP allow for deeper insights into the decision process of DNNs compared to traditional heatmaps, therefore improving the detection of potential model biases. In [3], we apply CRP to segmentation and object detection models to reveal concepts that focus on the background instead of the localized object, highlighting potential context bias. Targeting all kinds of biases, we present in [4] an Explainable AI life cycle with CRP to reveal and revise spurious model behavior.
References
| [1] | Reduan Achtibat, Maximilian Dreyer, Ilona Eisenbraun, Sebastian Bosse, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. “From attribution maps to human-understandable explanations through Concept Relevance Propagation”. In: Nature Machine Intelligence 5.9 (Sept. 2023), pp. 1006–1019. ISSN: 2522-5839. DOI: 10.1038/s42256-023-00711-8. URL: https://doi.org/10.1038/s42256-023-00711-8. |
| [2] | Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. “On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation”. In: PLOS ONE 10.7 (July 2015), pp. 1–46. DOI: 10.1371/journal.pone.0130140. URL: https://doi.org/10.1371/journal.pone.0130140. |
| [3] | Maximilian Dreyer, Reduan Achtibat, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. “Revealing Hidden Context Bias in Segmentation and Object Detection through Concept-specific Explanations”. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 2023, pp. 3829–3839. DOI: 10.1109/CVPRW59228.2023.00397. URL: https://doi.org/10.1109/CVPRW59228.2023.00397. |
| [4] | Frederik Pahde, Maximilian Dreyer, Wojciech Samek, and Sebastian Lapuschkin. “Reveal to Revise: An Explainable AI Life Cycle for Iterative Bias Correction of Deep Models”. In: Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. Ed. by Hayit Greenspan et al. Cham: Springer Nature Switzerland, 2023, pp. 596–606. ISBN: 978-3-031-43895-0. DOI: 10.1007/978-3-031-43895-0_56. URL: https://doi.org/10.1007/978-3-031-43895-0_56. |