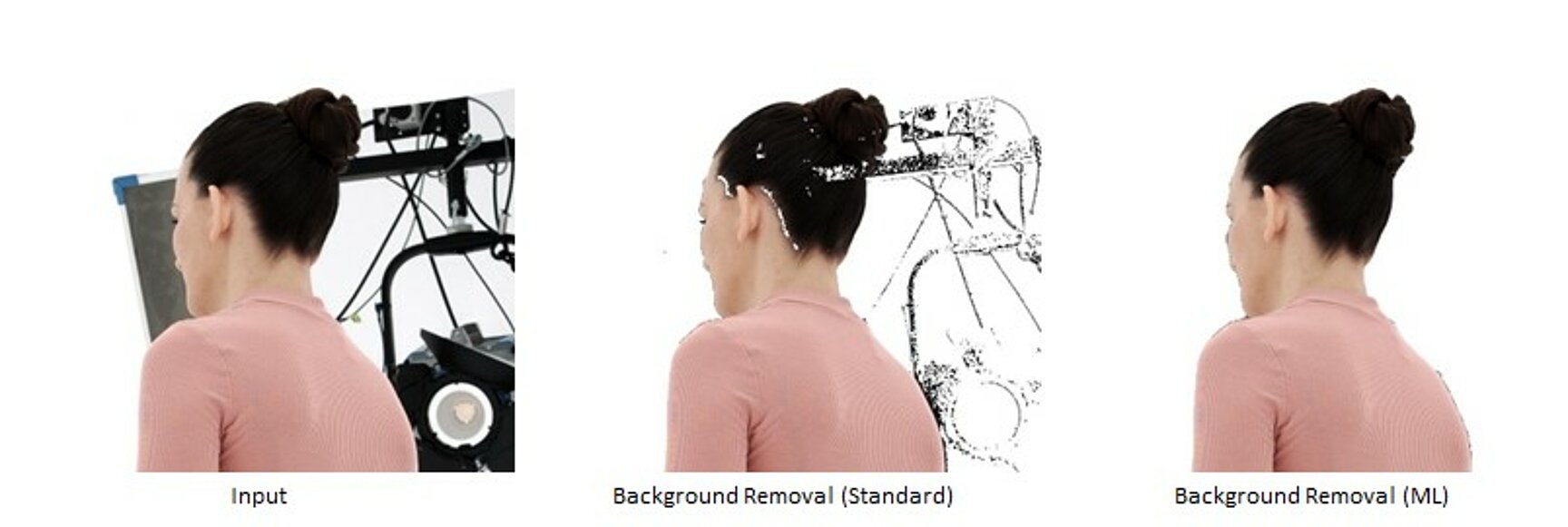
Foreground–background segmentation is a key module in the volumetric video pipeline. The standard segmentation mode is based on a method which learns a statistical model of the background for each camera using recordings of an empty studio (“clean plates”). In many cases, this model has difficulties coping with foreground color similar to the background. Hence, we developed an alternative method based on deep learning (Lin et al. 2021). This approach was fine-tuned on hundreds of manually labelled images from current and past volumetric capture data. The machine learning segmentation outperforms the statistical per-pixel approach most notably at resolving local ambiguities, i.e., when a foreground pixel has a similar color as the clean plate pixel at the same location. On the other hand, the statistical approach is faster and less heavy on GPU memory.
Lin, S., et al. "Real-time high-resolution background matting." IEEE/CVF CVPR, 2021