Video-driven animation refers to the task of transferring the facial expression from the video of a source actor to an animatable face model or avatar. This type animation has many potential applications such as video conferencing, virtual reality, and remote training/education but can also be used for creative works such as video-production or game-development.
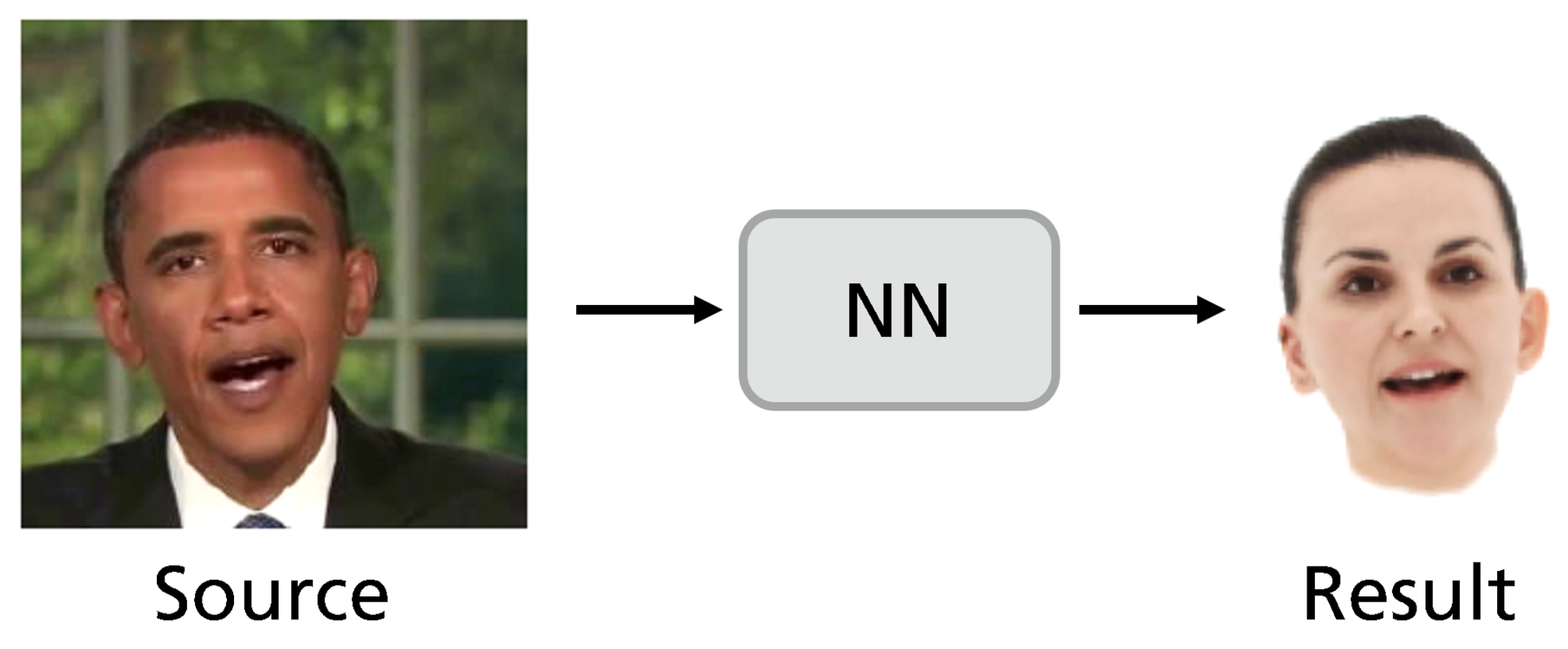
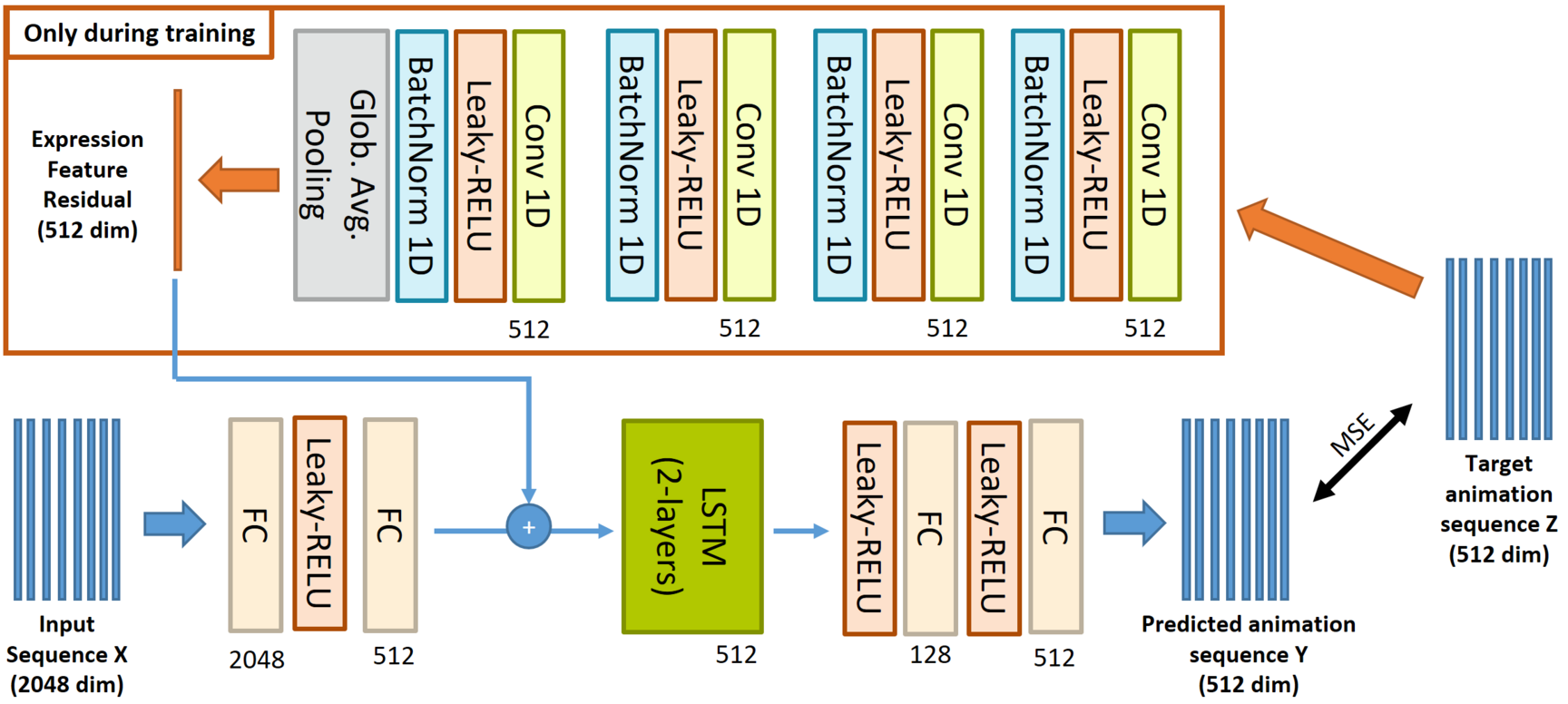
In order to drive our personalized head models from captured video data of arbitrary persons, we developed a new video-driven animation approach. The key-idea is to employ a pre-trained expression analysis network that provides subject-independent expression information. We then train a subsequent network that learns transforming these expression features into suitable animation parameters driving our head avatars.
The main challenge of this approach is the ambiguous mapping between subject-independent source expression features and the target expression parameters. To avoid these problems we make three improvements compared to a naïve approach:
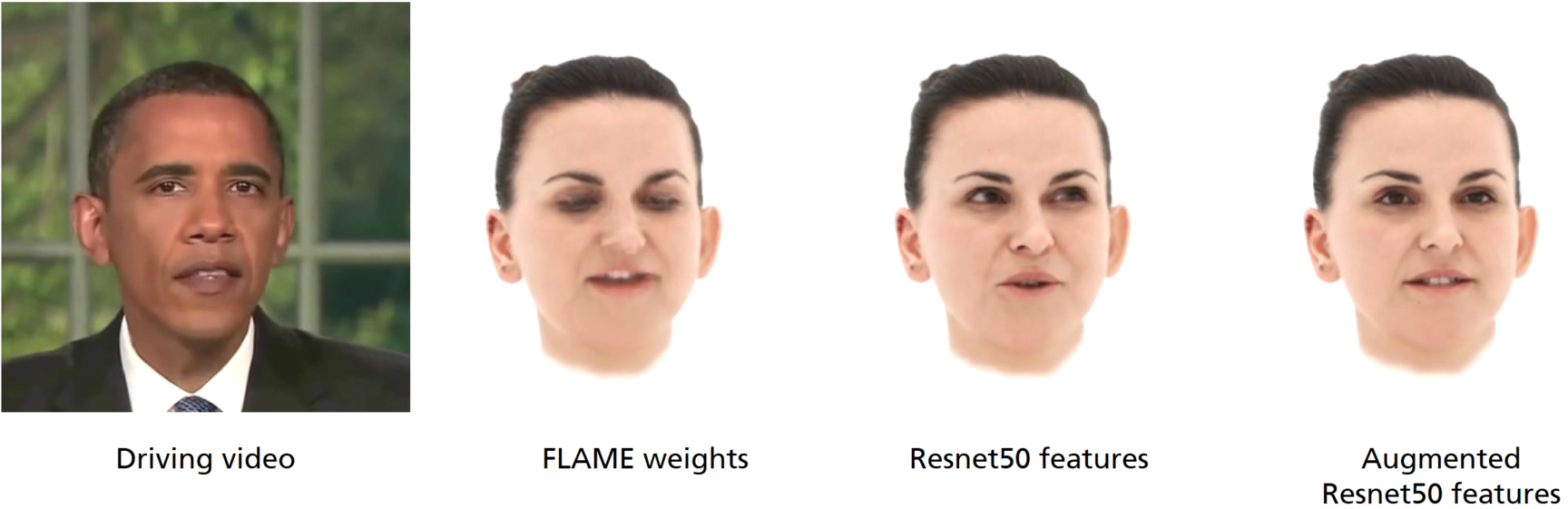
- We do not directly use the expression parameters predicted by the method of Feng et al., but rather use low-level expression features of the Resnet50 backbone.
- We make use of temporal relationships by employing an LSTM-based architecture that resolves some ambiguities via the temporal context.
- We introduce a residual expression encoder that computes residual features from the target animation parameters helping to capture expressions that can be explained neither from the Resnet50 features nor from the temporal context.
Neural Style Aware Animation
In order to gain more control over the synthesized animations, we also implemented a fully learning-based method that is able to animate the complete face (incl. mouth, eyes, brows) as well as the head-pose.
The key parts of our architecture are:
- A CNN based core animation network that transforms a sequence of expression labels (visemes) into an equally long sequence of animation parameters
- A style encoder CNN that extracts a latent style feature vector from the ground truth animation sequence.
- Two learned animation priors that regularize synthesized eye expressions and head movements.
The core animation network is conditioned on the latent style vector, which helps to represent variance in the training data that cannot be explained by the input viseme sequence alone. The animation priors are trained as sequence auto-encoders that transform the raw animation signal into realistic animation parameters for eyes and head pose.
The residual encoder is a 1D-CNN that extracts a single feature vector from a short sequence of ground-truth animation parameters. This residual feature is added to the person-independent expression parameters and helps resolving ambiguities during training without providing short-term expression information.
Apart from improving the animation accuracy, the learned residual expression space can be used to fine-tune synthesized animation during inference, which is especially useful for creative tasks.

Videos
Publications
W. Paier, P. Hinzer, A. Hilsmann, P. Eisert
Video-Driven Animation of Neural Head Avatars, Vision, Modeling, and Visualization, The Eurographics Association Braunhschweig, Germany, September 2023. doi: 10.2312/vmv.20231237