Speech-/Text-based Animation
Speech/text-driven animation is a convenient method for animating a human avatar based on speech content that is especially useful in application scenarios where video-based capture of a human actor is not possible or when no humans are in the loop (e.g. virtual assistants). We have developed various animation methods for our neural head model representation based on viseme input such that our avatars can be driven by either speech or text.
Example-based Animation
The idea of example-based animation is re-using/re-arranging short animation samples in order to synthesize novel performances of virtual characters. For speech animation we simply concatenate short dynamic mouth expressions (visemes) depending on the spoken words/syllables. The main task of the animation algorithm is selecting an optimal sequence of animation samples from a database that, when concatenated, yields a plausible and realistic mouth animation without artifacts at the transition points. We solve this problem by minimizing an objective function consisting of a data term U that ensures that only samples with the correct viseme-labels are selected and a smoothness term B ensuring that transitions between concatenated samples contain no artefacts.
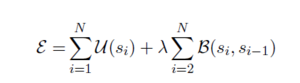
Our animation database is created automatically with the help of forced-alignment, which provides an accurate phonetic alignment of spoken text with a captured audio-track.

Neural Style Aware Animation
In order to gain more control over the synthesized animations, we also implemented a fully learning-based method that is able to animate the complete face (incl. mouth, eyes, brows) as well as the head-pose.
The key parts of our architecture are:
- A CNN based core animation network that transforms a sequence of expression labels (visemes) into an equally long sequence of animation parameters
- A style encoder CNN that extracts a latent style feature vector from the ground truth animation sequence.
- Two learned animation priors that regularize synthesized eye expressions and head movements.
The core animation network is conditioned on the latent style vector, which helps to represent variance in the training data that cannot be explained by the input viseme sequence alone. The animation priors are trained as sequence auto-encoders that transform the raw animation signal into realistic animation parameters for eyes and head pose.
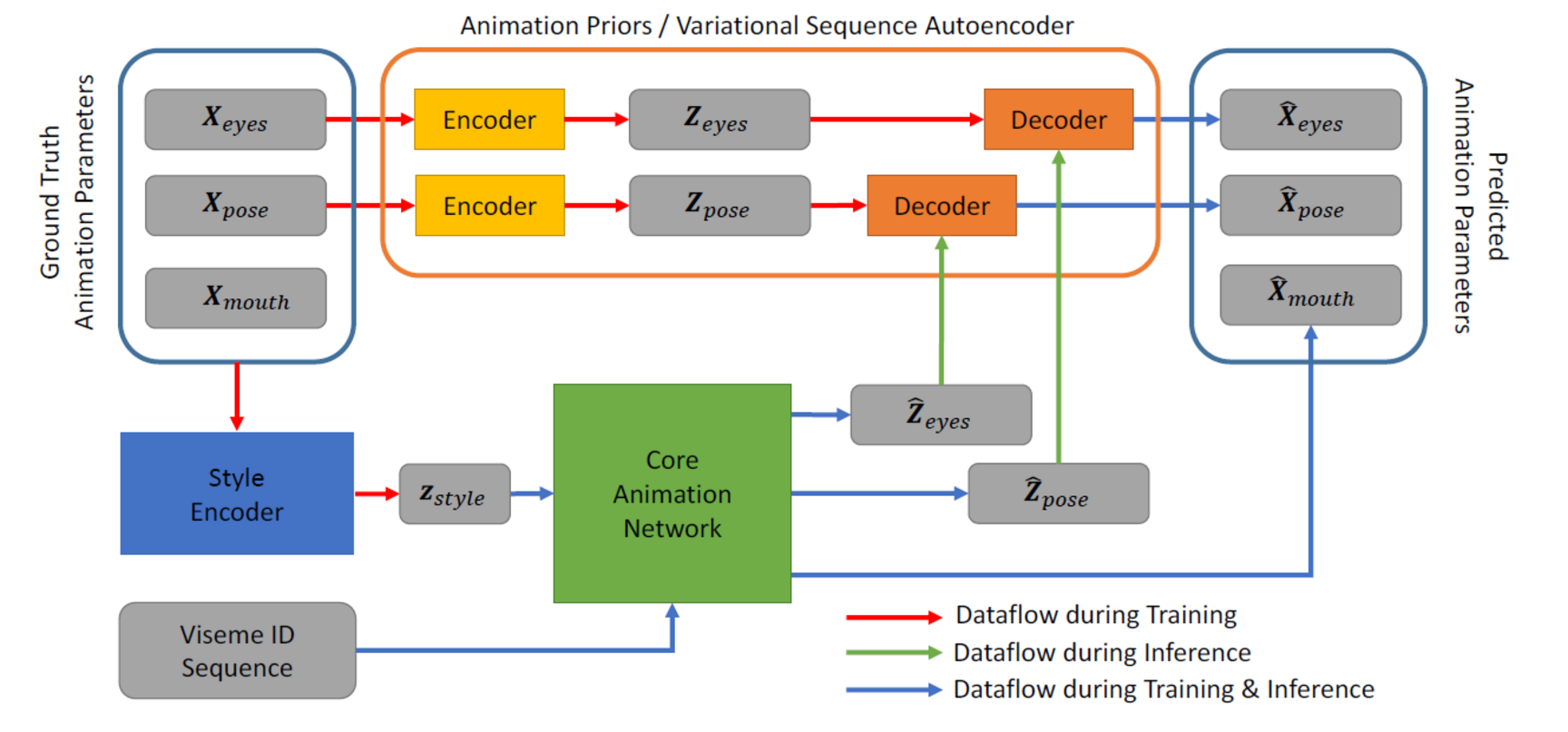
Our animation method can be trained on emotional speech sequences without manually selected or pre-computed style/emotion labels, since the latent animation-style-space is constructed automatically during training. This improves the animation quality and enables convenient refinement of synthesized animations during inference. Moreover, the animation priors ensure artefact-free animation of parts that are not well correlated with speech such as eyes and head-pose enabling training on challenging data such as real acting sequences.

Videos
Publications
W. Paier, A. Hilsmann, P. Eisert
Unsupervised Learning of Style-Aware Facial Animation from Real Acting Performances, Graphical Models, October 2023. [arXiv] doi: 10.1016/j.gmod.2023.101199
W. Paier, A. Hilsmann, P. Eisert
Example-Based Facial Animation of Virtual Reality Avatars using Auto-Regressive Neural Networks, IEEE Computer Graphics and Applications, March 2021, doi: 10.1109/MCG.2021.3068035, Open Access
W. Paier, A. Hilsmann, P. Eisert
Neural Face Models for Example-Based Visual Speech Synthesis, Proc. of the 17th ACM SIGGRAPH Europ. Conf. on Visual Media Production (CVMP 2020) London, UK, Dec. 2020. Best Paper Award, Doi: 10.1145/3429341.3429356
W. Paier, A. Hilsmann, P. Eisert
Interactive Facial Animation with Deep Neural Networks, IET Computer Vision, Special Issue on Computer Vision for the Creative Industries, May 2020, Doi: 10.1049/iet-cvi.2019.0790