Neural representations of 3D human heads & faces have various potential applications. For example virtual/augmented reality, immersive communication, virtual assistants or creative tasks such as video-editing and game design. At HHI, we developed a hybrid framework for modelling, animation, and rendering of human heads based on captured multi-view video that helps to realize the aforementioned tasks. The remainder of this page gives an overview of the full processing pipeline, individual methods and demonstrates the achieved quality with still image and video results.
Performance Capture
Our facial performance capture is based on a hybrid strategy that combines blend shape geometry with highly detailed dynamic face textures. This enables efficient recovery of 3D facial geometry from multi-view video streams, while dynamic textures capture fine details, deformations, and complex areas that cannot be represented by the simple underlying blend shape model.
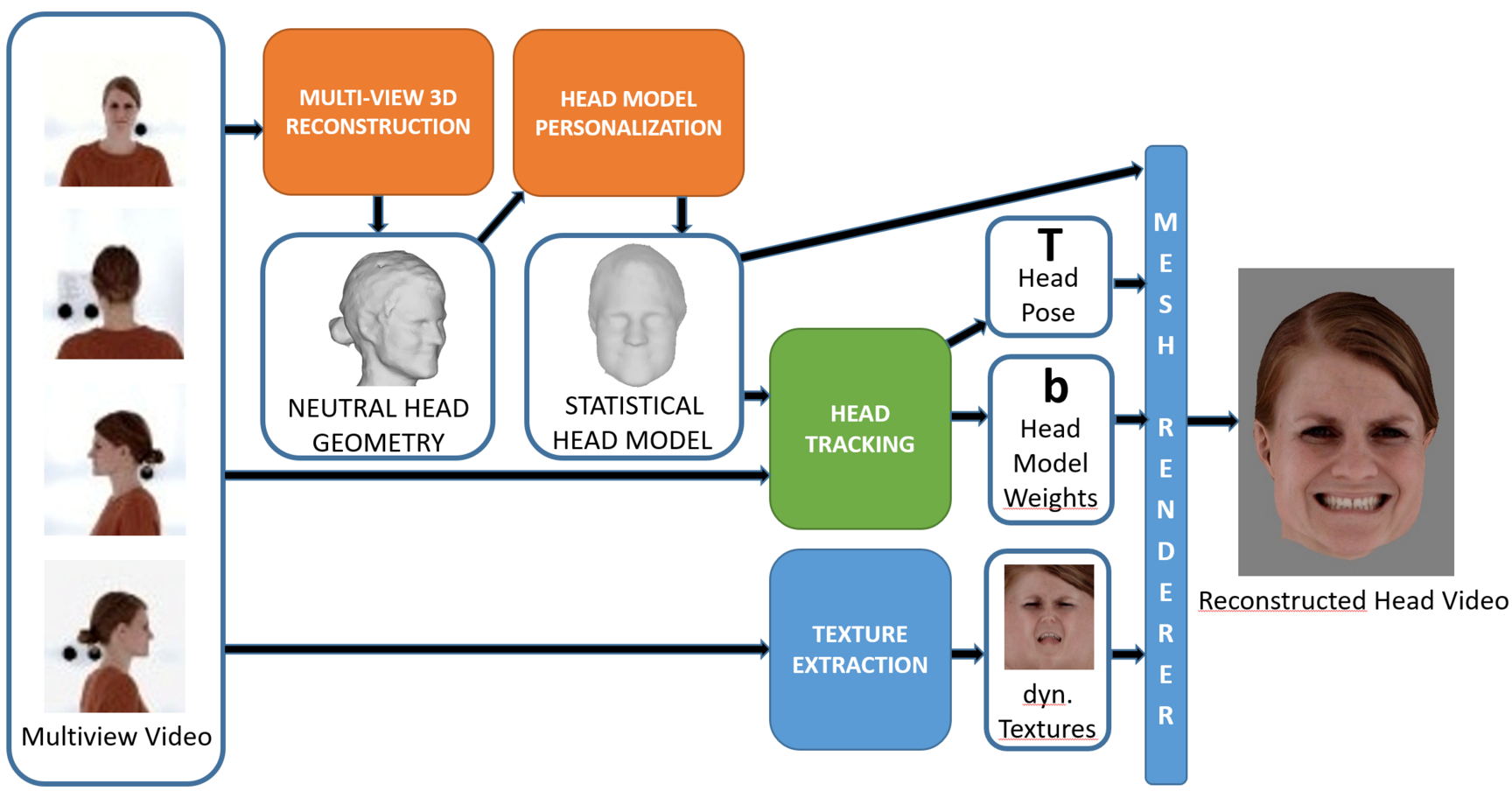
Head Model Learning
While the hybrid representation based on blend-shape geometry and dynamic textures allows for detailed replay of the captured facial performances, it does not facilitate interpolation or synthesis of facial expressions based on a compact parameter vector.
Therefore, we train a variational auto-encoder that learns a joint latent expression space for face geometry and texture. In order to preserve the high level of detail in synthesized face textures, we incorporate a texture-discriminator in the training process minimizing of blurriness synthetic textures.
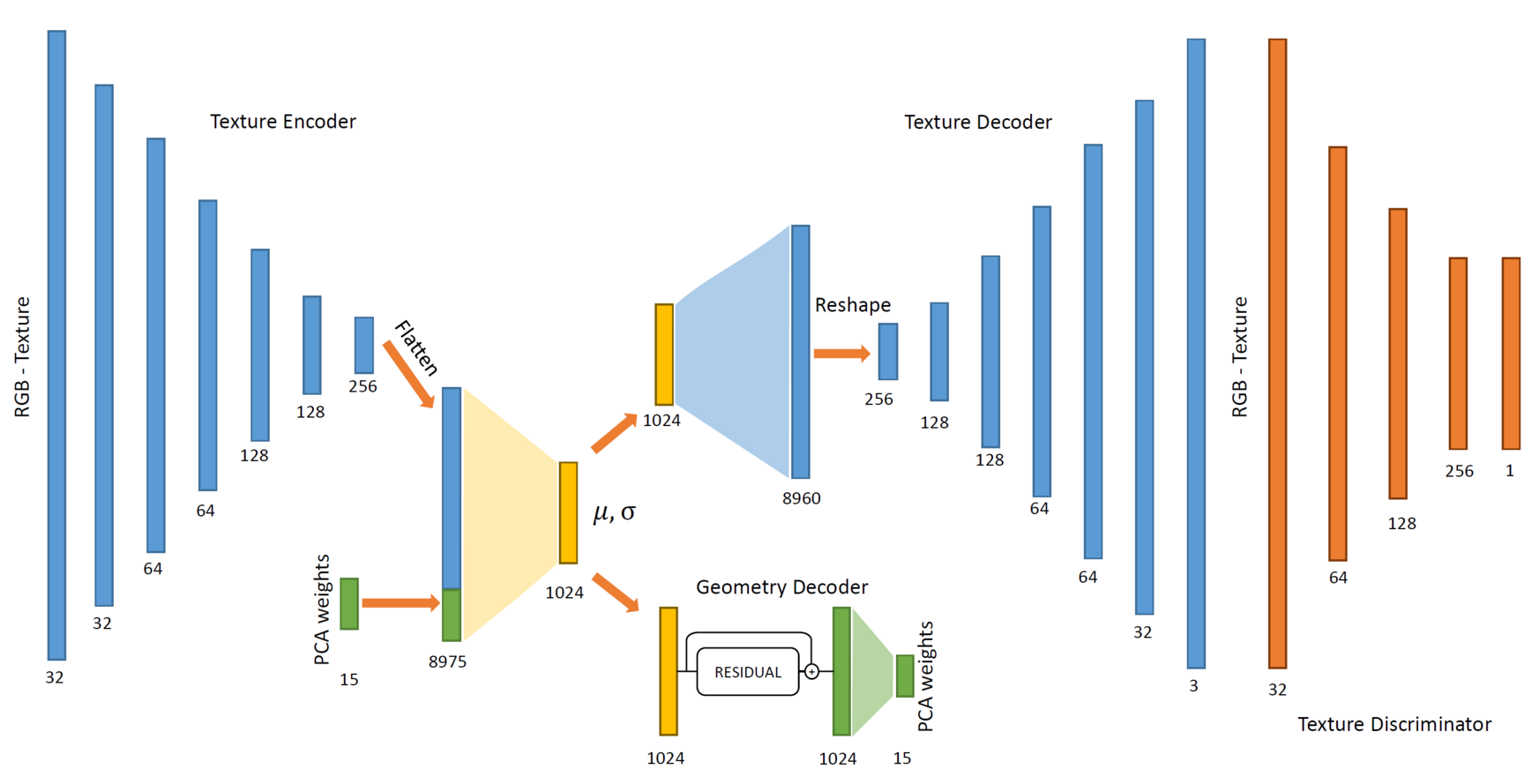
Neural Rendering
Photorealism plays an important role in todays and future VR applications and while the used mesh-plus-texture representation supports reconstructing detailed facial expressions as well as most of the appearance, several important features are missing. This decreases the perceived realism of rendered images, as for example the silhouette appears unnaturally clean and lacks details, hair cannot be rendered realistically and view-dependent effects are missing. Therefore, we introduce a U-Net-based post-processing step that helps to transform a mesh-based rendering of a head model into a photo-realistic image of the captured person.
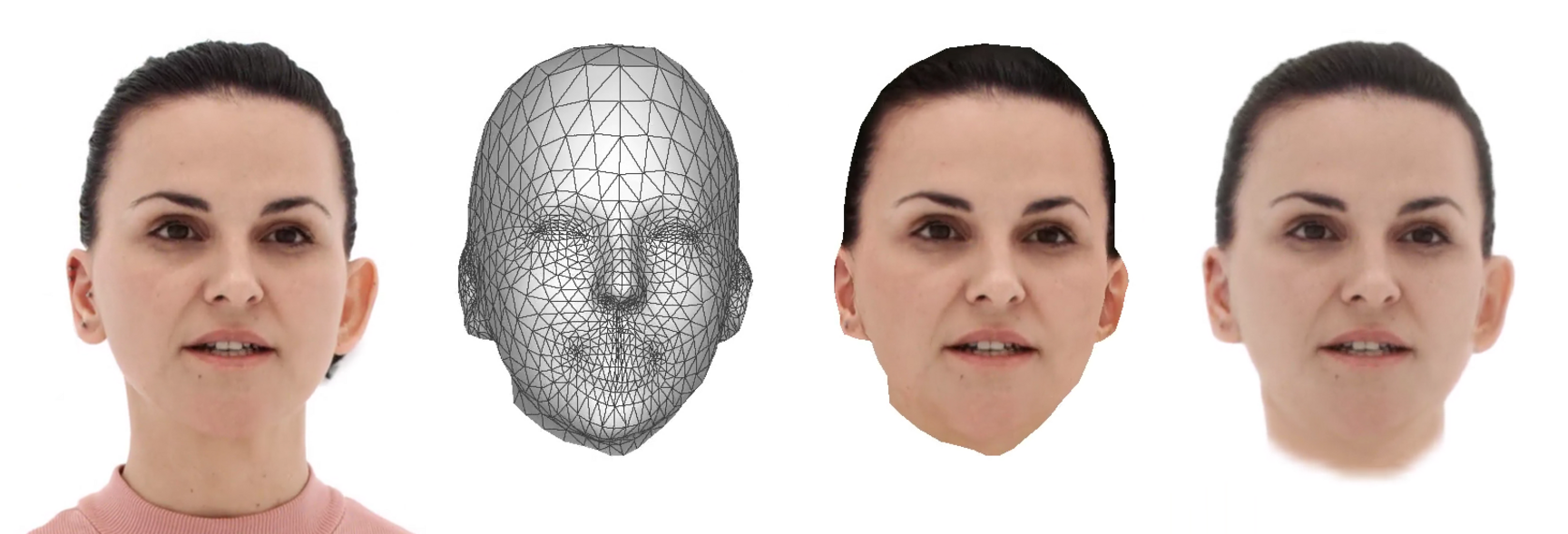
Taking into account that this approach should be capable of rendering the head model in 3D scenes, the network is trained with multi-view video data that shows the captured head from different viewpoints. To simplify the training process and support rendering the head model in front of arbitrary backgrounds, a self-supervised training regime is implemented that helps the network to separate foreground from background via alpha masks. This also simplifies the training process, as no pre-computed foreground masks are necessary.
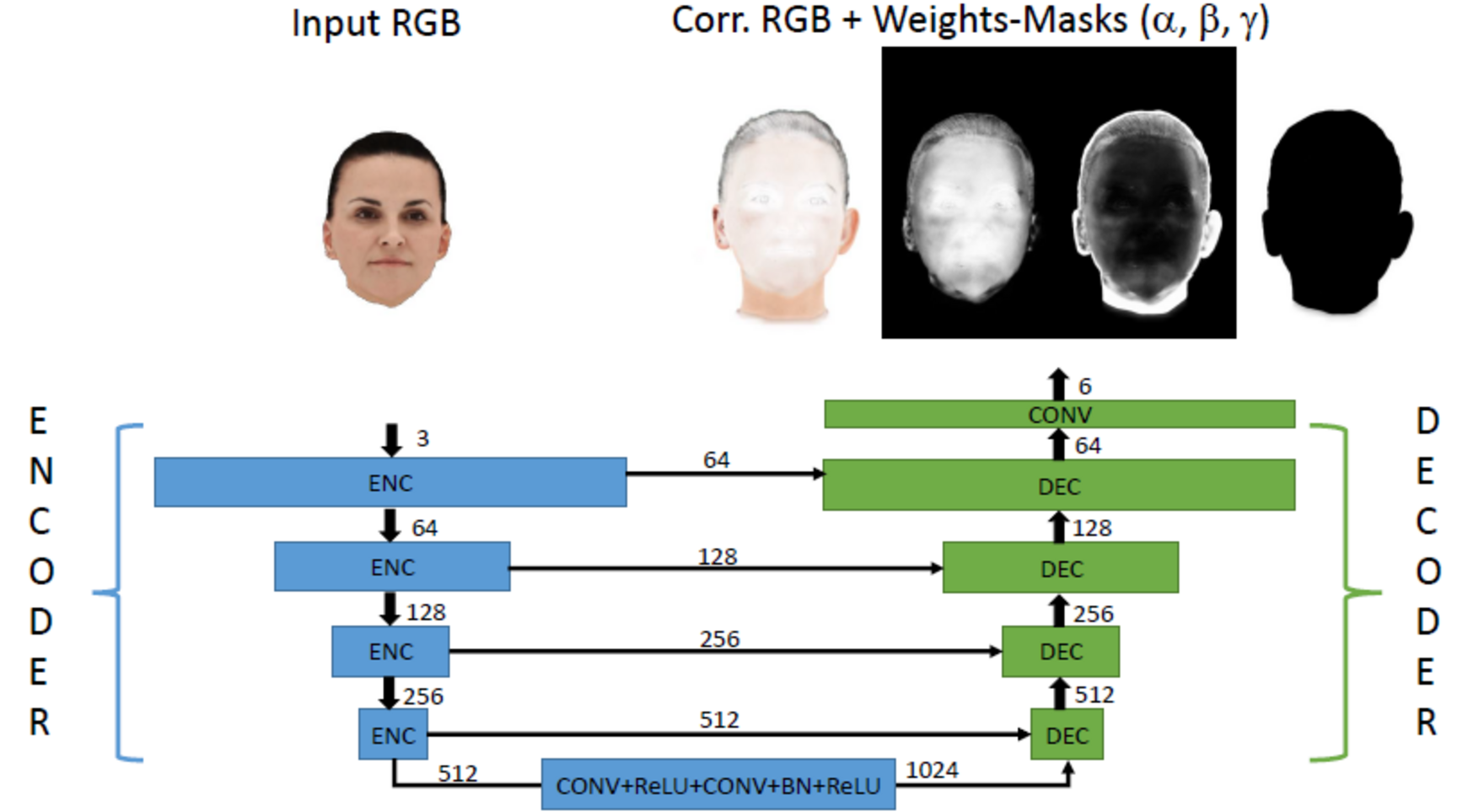
Image Formation Model
The image formation model of the employed neural rendering approach can be expressed as a convex combination of the mesh-based rendering, a corrective image and the static background, where each image contributes according to spatially varying weight maps that sum up to one at every pixel.
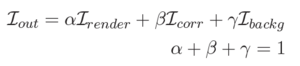
The motivation for this image formation model is the fact that the rendered hybrid head model together with a clean plate as a background provides already a good approximation of the captured scene. Corrections are mostly necessary at the silhouette and in complex areas (e.g. oral cavity, eyes, hair) where the 3D geometry is not accurate enough or material properties are too complex to be represented by a single diffuse texture.
Videos
Publications
W. Paier, A. Hilsmann, P. Eisert
Example-Based Facial Animation of Virtual Reality Avatars using Auto-Regressive Neural Networks,
IEEE Computer Graphics and Applications, March 2021, doi: 10.1109/MCG.2021.3068035, Open Access
W. Paier, A. Hilsmann, P. Eisert
Neural Face Models for Example-Based Visual Speech Synthesis,
Proc. of the 17th ACM SIGGRAPH Europ. Conf. on Visual Media Production (CVMP 2020) London, UK, Dec. 2020. Best Paper Award
W. Paier, A. Hilsmann, P. Eisert
Interactive Facial Animation with Deep Neural Networks,
IET Computer Vision, Special Issue on Computer Vision for the Creative Industries, May 2020, Doi: 10.1049/iet-cvi.2019.0790